Reinforcement Learning with Human Feedback as a Knowledge Distillation Tool
This project targets the algorithms behind the massively successful applications of
Reinforcement Learning with Human Feedback, which is the training process behind ChatGPT, LLaMA II,
and plenty other instruction-tuned language models. Specifically, Proximal Policy Optimization
provides a routine for training a policy model to optimize a scalar reward. As with many other
domain applications in RL, without proper guard rails the model will simply hack this reward, and
generate outputs which have very high reward values but do not maintain the desired semantic and lexical
integrity.
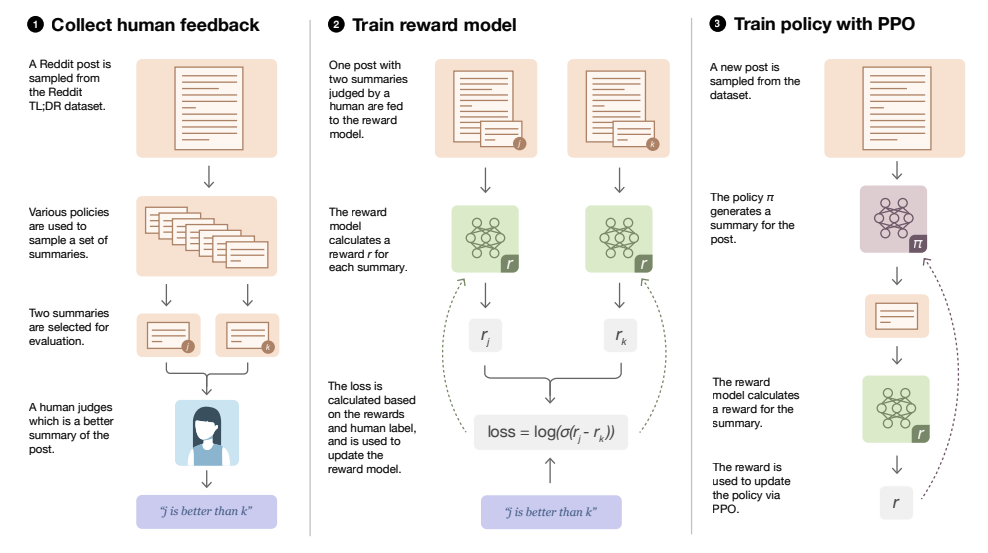
One aspect of modern PPO implementations which addresses this is the creation of a
"reference model", a copy of the policy model created before any RL training occurs. Then, each
token-wise generation of the policy model is compared to the reference model and an "active-token"
Kullback-Leibler divergence approximation is computed. The policy model is tasked with minimizing this
divergence while maximizing the scalar reward, creating a less-hackable optimization landscape.
This can be formulated as follows (source):
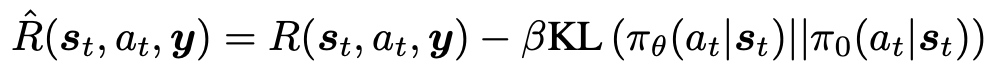
The original research question for this project was "How do we incorporate stimuli from API-restricted
large language models which we do not have access to the parameters of?" and our focus quickly
landed on utilizing these reference models to do so. While testing the use of various reference models,
it becomes quickly apparent that there is some type of traditional knowledge distillation occuring
in this RL setting. We then have turned our investigation toward understanding and describing this
knowledge distillation which is more apparent when a different sized reference model is utilized.
The current
research repository is built off of Allen-AI's RL4LMs modular repository and can be found
here. This project is under advisement by Dr.
Kartik Goyal and the computational resources in which our experiments are conducted on are
supplied by Toyota Technical Institute of Technology. For collaboration or inquiries, please
feel free to contact me via email.